RAGLab
Problem tier down for a retrieval benchmark lab that compares RAG strategies on the same datasets with visible evidence, scores, latency, and method ranking.
Concept
Teams cannot know which RAG method works best unless every method is tested on the same data.
Most RAG demos show one retrieval path and one answer, so users cannot compare BM25, vector, hybrid, memory, graph, or field-aware retrieval fairly. RAGLab solves this by running multiple retrieval strategies on the same dataset and showing retrieved evidence, relevance, coverage, latency, score, and recommendation ranking.
User Personas
Ananya Rao
AI Product Manager
- Age
- 31
- Context
- Owns an internal AI assistant roadmap and needs to select the right retrieval strategy before scaling.
- Behavior
- Compares demos, asks quality questions, checks latency, and needs a product-facing recommendation.
- Pain
- Cannot defend “vector RAG is enough” without evidence across multiple data types and query types.
Karan Mehta
ML Engineer
- Age
- 28
- Context
- Builds retrieval pipelines and needs to inspect chunks, scoring, embeddings, graph links, and edge cases.
- Behavior
- Runs experiments, changes datasets, compares retrieved evidence, and studies failure modes.
- Pain
- Evaluation is fragmented across notebooks, logs, vector stores, and manual judgment.
Meera Shah
Data Analyst
- Age
- 34
- Context
- Uses RAG outputs for operational reporting, compliance support, and internal knowledge search.
- Behavior
- Checks citations, asks exact-term questions, validates source rows, and compares answer reliability.
- Pain
- Trust is low when answer evidence, score, coverage, and retrieval method are not visible.
Selected User Persona
Ananya Rao, AI Product Manager
Ananya is the strongest starting persona because she owns the product decision: which RAG strategy should be shipped, how it should be explained to stakeholders, and what evidence proves that the selected method is reliable. Her workflow naturally tests product usability, retrieval quality, evidence visibility, latency, and method recommendation in one journey.
User Journey Map
| Journey Stage | Actions | Emotion | Pain Points | Opportunities |
|---|---|---|---|---|
| Choose Dataset | Ananya selects a demo dataset such as architecture notes, support tickets, retail orders, a runbook, QA fixtures, or graph triples. | Curious 🤔 | She does not know whether the dataset needs semantic search, exact keyword matching, graph traversal, or field-aware lookup. | Show compact EDA: corpus count, chunks, top terms, samples, and suggested retrievers. |
| Ask Question | She runs a prepared benchmark query or writes a custom question for the selected dataset. | Focused 🎯 | A single query can require exact identifiers, semantic paraphrase handling, structured fields, or entity relationships. | Route the same query through multiple methods so comparison is fair. |
| Compare Methods | Reviews BM25, vector, hybrid, memory, graph, and field-aware outputs. | Analytical 🔍 | Without shared scoring, every method looks correct in isolation and weak decisions can hide behind polished answers. | Show score, relevance, coverage, latency, and evidence count side by side. |
| Inspect Evidence | Checks retrieved chunks, citations, source rows, and token telemetry. | Cautious ✅ | She cannot trust a recommendation if the evidence trail is hidden or the top method lacks support. | Expose retrieved evidence, source snippets, scoring components, and method reasoning. |
| Select Strategy | She uses the ranked result to decide which RAG strategy should become the product default. | Confident 🚀 | Raw outputs are not enough; she needs a clear explanation for why one strategy wins. | Recommend the best method for the dataset and query type, with tradeoffs visible. |
Pain Points
No Fair RAG Comparison
Teams usually compare retrieval approaches through separate demos, notebooks, or vendor examples. Because the dataset, query, scoring, and evidence view are different, the comparison becomes opinion-driven instead of product-driven.
Evidence Is Hidden
A RAG answer is only useful when the user can inspect what was retrieved. Without chunks, citations, coverage, method score, and latency, users cannot explain why the answer should be trusted.
Different Data Needs Different Retrieval
Markdown notes, QA JSON, runbooks, ticket JSONL, CSV orders, and graph triples behave differently. A single vector-only approach can fail on exact terms, identifiers, structured fields, or relationship-heavy questions.
Method Choice Is Unclear
BM25, vector, hybrid, memory, graph, and field-aware RAG all solve different retrieval problems. Builders need a practical product interface that explains when each method wins and why.
Latency And Cost Are Invisible
A high-quality answer can still be a poor product choice if it is slow or expensive. Teams need latency, evidence count, token telemetry, and score signals visible before selecting a production method.
Evaluation Workflow Is Fragmented
Data loading, chunking, indexing, querying, result comparison, and evidence inspection often live in separate scripts or notebooks. This makes iteration slow and difficult to communicate to non-engineering stakeholders.
Pain Point Prioritization
| No. | Pain Point | Time | Effort |
|---|---|---|---|
| 01 | No fair RAG comparison | ||
| 02 | Evidence is hidden | ||
| 03 | Different data needs different retrieval | ||
| 04 | Method choice is unclear | ||
| 05 | Latency and cost are invisible | ||
| 06 | Evaluation workflow is fragmented |
Solutions
OK Ideas
Shows one retrieval path, but it does not prove why that method should be trusted over other approaches.
Documents retrieval scores after experiments, but it is not interactive enough for product or stakeholder review.
Useful for engineering experiments, but too fragmented for non-technical decision makers.
Best Ideas
Runs the same query across BM25, vector, hybrid, memory, graph, and field-aware retrieval.
Shows retrieved chunks, citations, relevance, coverage, latency, token telemetry, and scoring logic.
Ranks retrieval strategies and explains which method fits the dataset and question type.
Moonshots
Interactive lab that compares methods, explains tradeoffs, and recommends the strongest retrieval strategy.
Automatically selects BM25, vector, hybrid, graph, memory, or field-aware retrieval based on query intent.
Connects real enterprise datasets, permission rules, evaluation telemetry, and production readiness scoring.
Moonshot Prioritization
| No. | Moonshot | Time | Effort |
|---|---|---|---|
| 01 | RAGLab Method Intelligence Lab | ||
| 02 | Retrieval Auto-router | ||
| 03 | Enterprise RAG Evaluation Suite |
Selected Solution
RAGLab Method Intelligence Lab
RAGLab Method Intelligence Lab is the selected solution because it connects product decision making, retrieval engineering, and evidence inspection in one workflow. Instead of showing a single polished RAG answer, the system runs the same question through multiple retrieval methods and explains which method should be trusted for the selected dataset and query type.
Solution Architecture
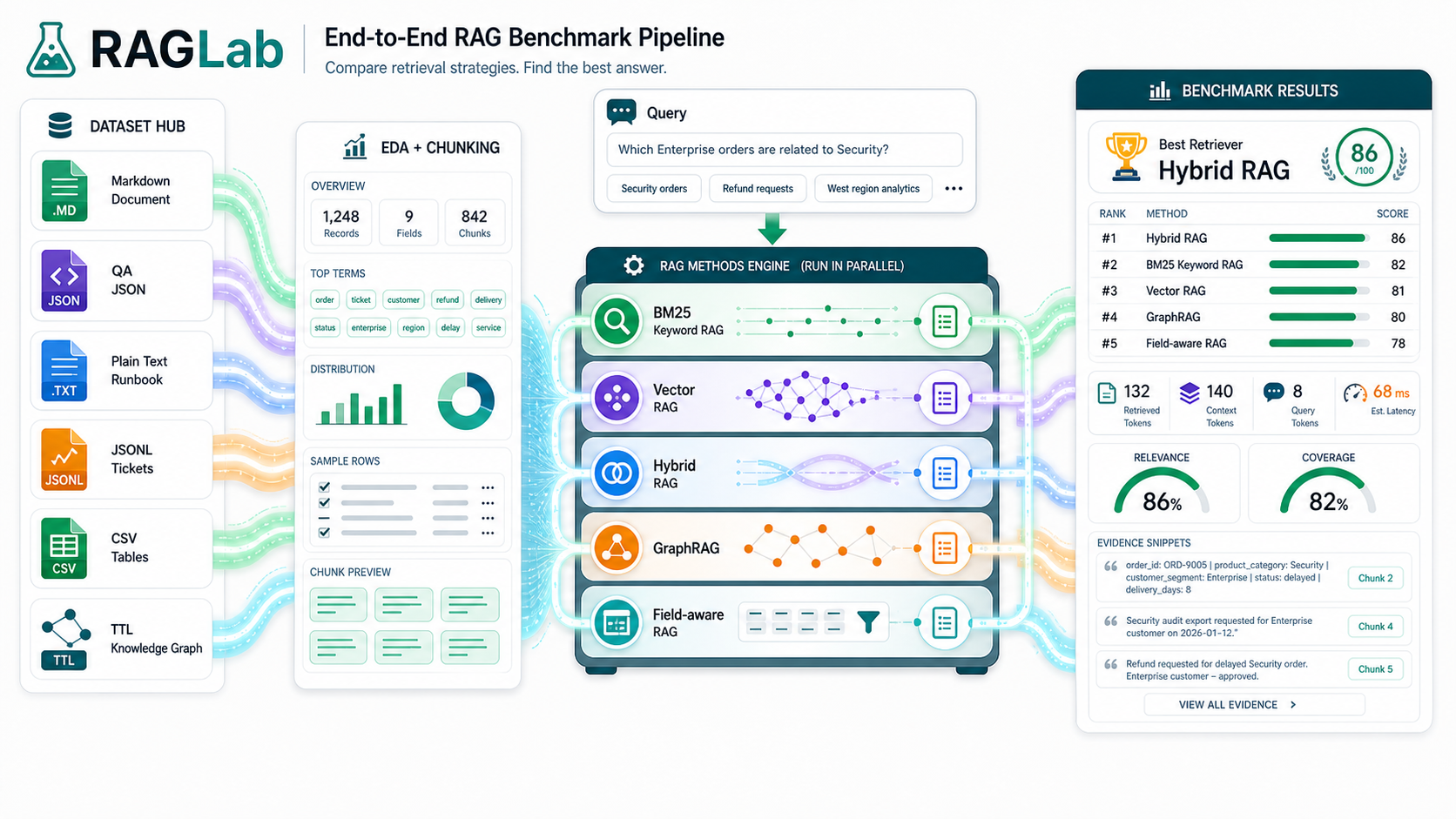
Solution Explanation
Users select structured and unstructured demo datasets such as notes, QA fixtures, runbooks, support tickets, orders, and graph triples.
The same prepared or custom question runs across every retrieval method so the comparison remains fair.
BM25, vector, hybrid, memory, graph, and field-aware retrieval are compared inside one product surface.
Each answer exposes retrieved chunks, citations, source snippets, relevance, coverage, score, and latency.
The product ranks methods and explains why one retrieval strategy fits the current dataset and question better than others.
The hosted demo uses public-safe seeded data and can evolve toward Supabase, pgvector, full-text search, and adapter-based retrieval systems.
Evidence Screens
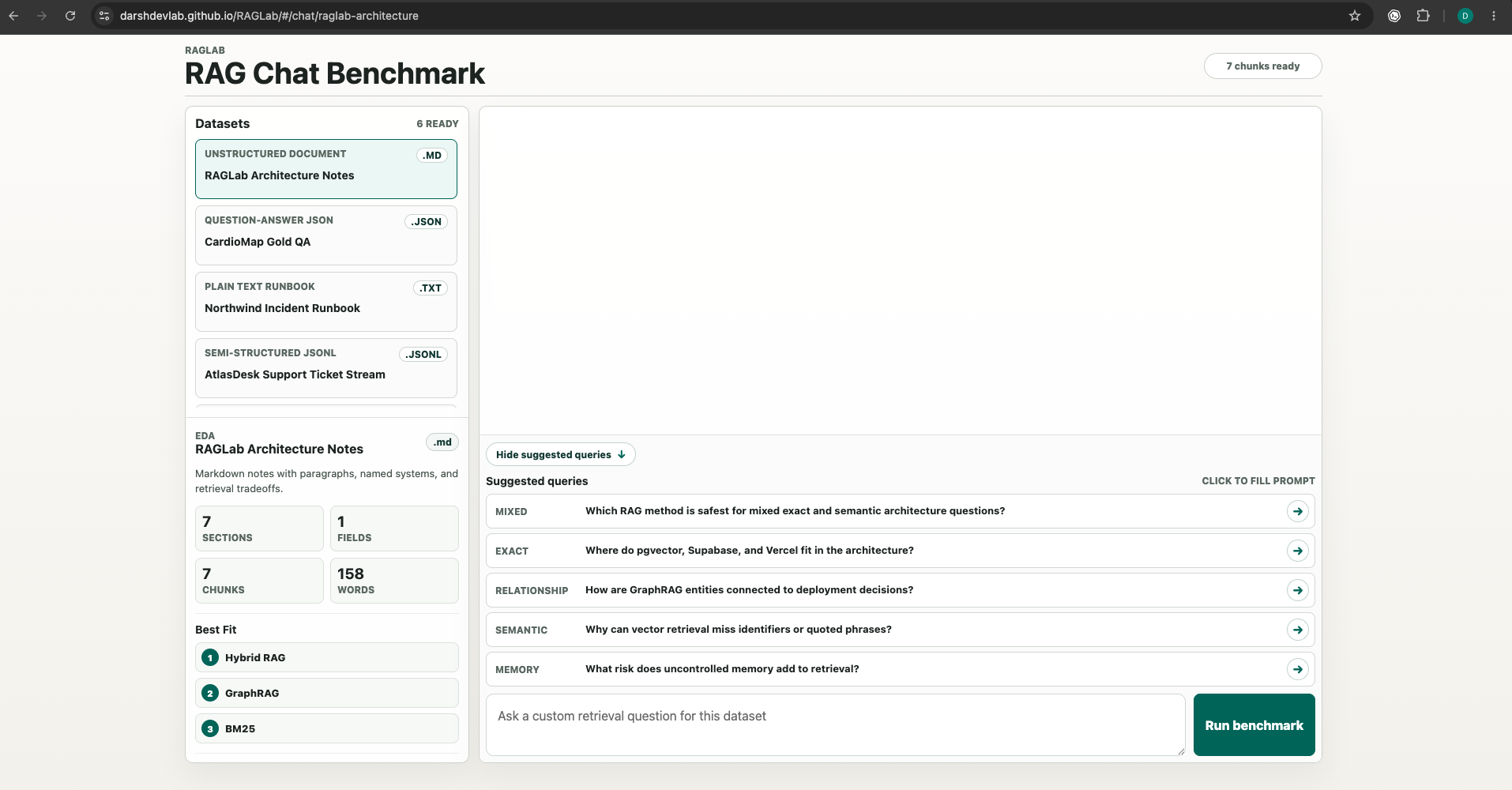
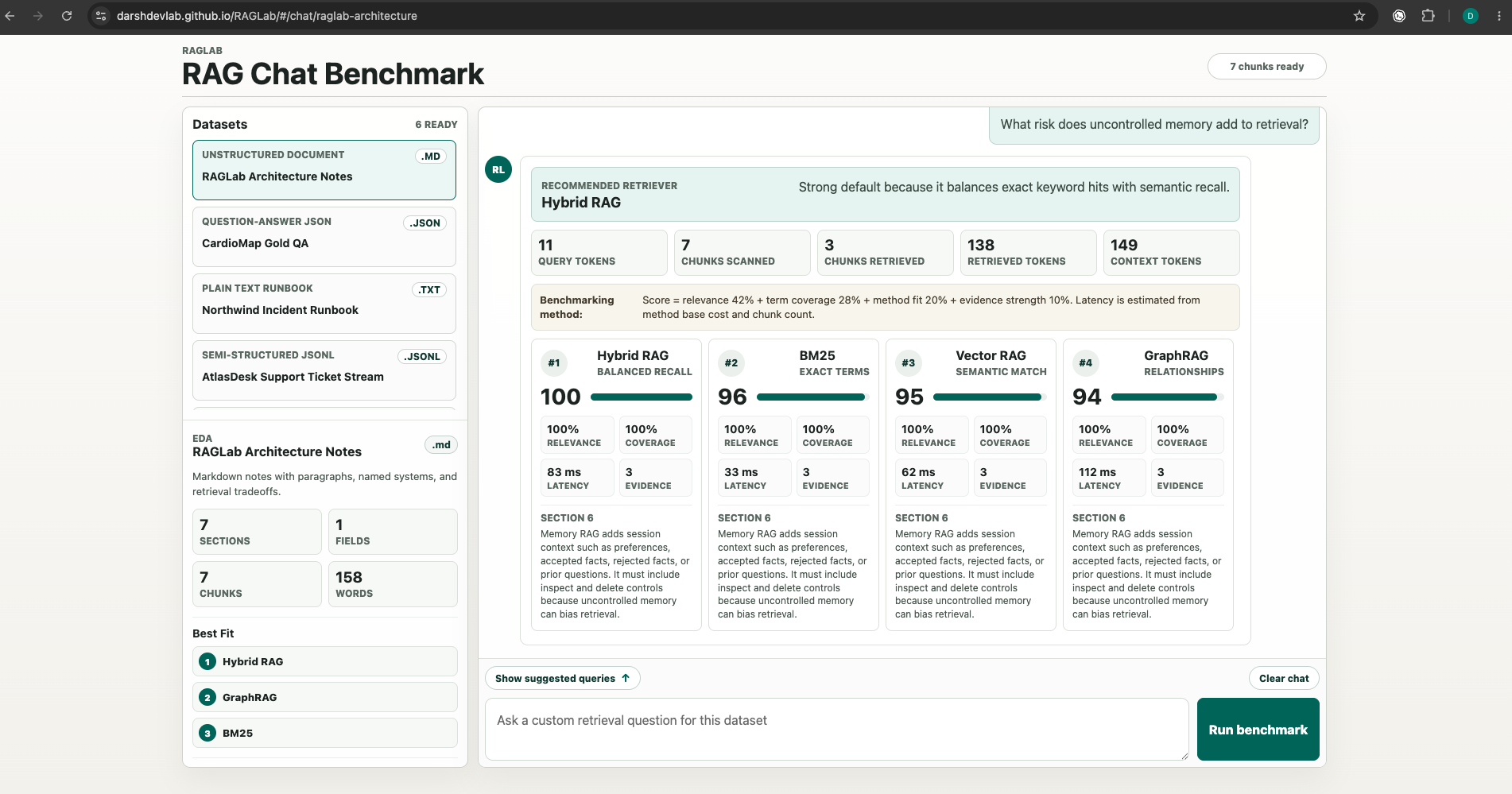
Final Product Direction
RAGLab is a retrieval benchmark product that helps AI builders compare RAG strategies with evidence instead of guessing. The product turns retrieval evaluation into a visible workflow: choose a dataset, ask a question, compare methods, inspect evidence, and select the best retrieval strategy for production.