About Product
1.1 What We Are Making
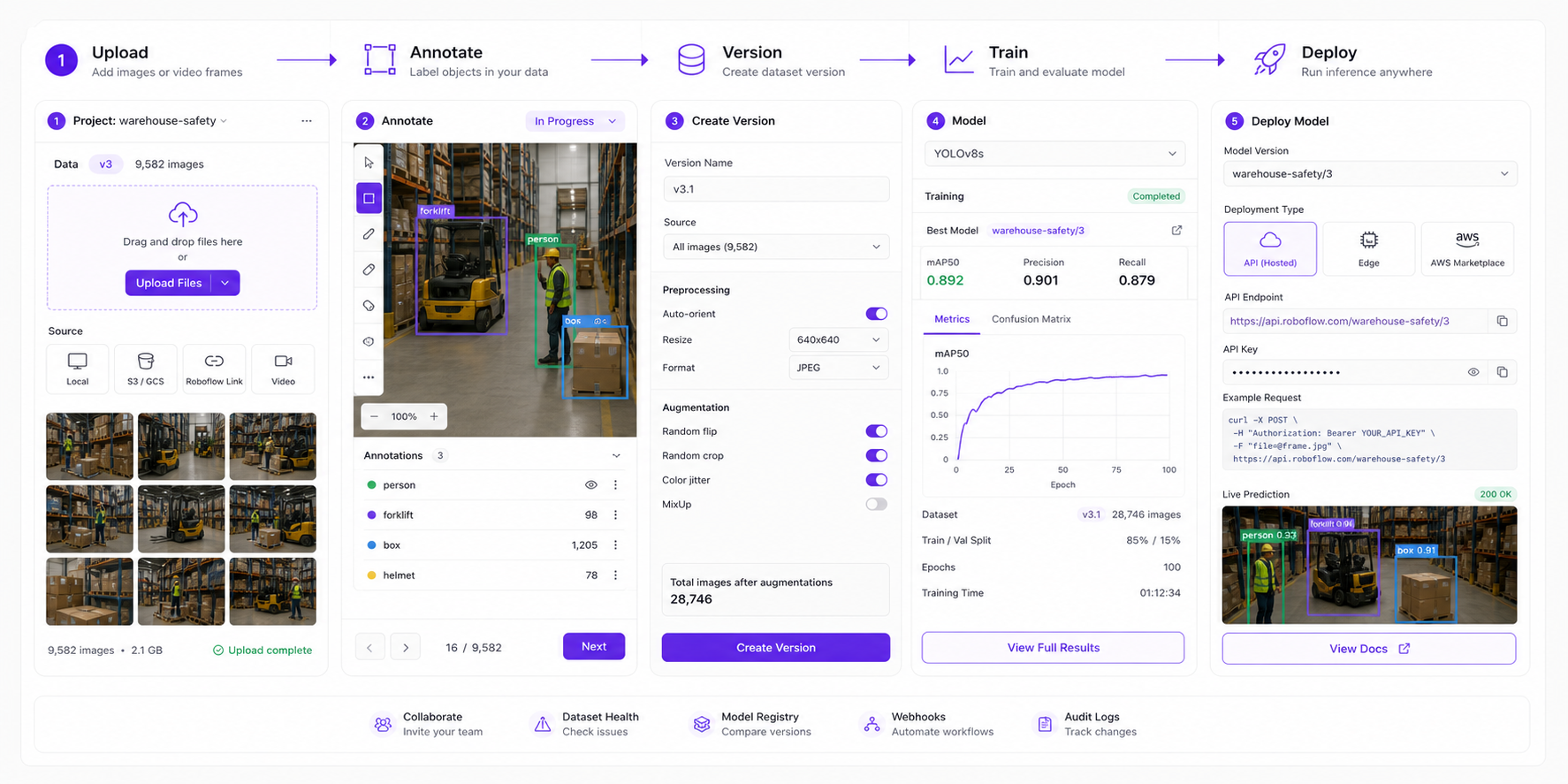
Roboflow Model Readiness Advisor is a workflow intelligence layer for computer-vision teams building, training, evaluating, and deploying models. It tells users whether their dataset, annotations, augmentation strategy, evaluation results, and deployment target are ready for production, then recommends the next best action.
Roboflow Model Readiness Advisor.
Computer-vision MLOps, dataset quality intelligence, model evaluation, and deployment readiness.
- Dataset and annotation quality scanner.
- Class balance, leakage, augmentation, and split diagnostics.
- Model performance explanation by class, scene, and confidence.
- Production readiness score for cloud, edge, or API deployment.
- Next-best-action plan for data collection, labeling, retraining, or deployment.
- Prevents premature deployment of weak vision models.
- Shortens label-train-evaluate iteration loops.
- Helps teams understand why a model fails in real scenes.
- Turns Roboflow from tooling into a decision system.
Vision teams often know how to upload and train, but not whether model behavior is safe enough for the target environment. Aggregate mAP can hide poor minority-class behavior, lighting failures, drift, and edge-device constraints.
Help teams move from model experimentation to production rollout with clear readiness, risk, and next-action guidance.
1.2 Who It Is For
| User cohort | Description | How they use it | Primary product promise |
|---|---|---|---|
| Vision builders | Developers and product teams building object detection, classification, or segmentation workflows. | Inspect dataset, train model, review readiness, fix weak classes. | Know what to improve before deployment. |
| Operations teams | Manufacturing, retail, safety, agriculture, and logistics teams using vision in real environments. | Validate model against deployment conditions and business risk. | Deploy only when model behavior is explainable enough. |
| ML platform teams | Teams managing many datasets, versions, and deployment endpoints. | Use readiness history to govern model rollout. | Standardize release quality across projects. |
1.3 Why We Are Building It
Background
Roboflow already covers upload, annotation, versioning, training, and deployment. The missing product layer is a clear answer to: “Is this vision model ready for the environment where it will be used?”
Assumptions
- Dataset and annotation quality strongly predict deployment failure.
- Users value actionable fix plans more than raw metrics.
- Deployment target constraints change readiness requirements.
- Roboflow can compute useful readiness from dataset metadata, eval metrics, and deployment telemetry.
Market Opportunity
Computer vision adoption is growing in operational workflows, but production trust remains a bottleneck. Readiness guidance creates a premium product surface beyond training.
Company Goals Alignment
- Increase successful deployments.
- Improve dataset/version retention.
- Lower support dependency around model quality questions.
- Differentiate Roboflow as a production-grade vision platform.
Feature Architecture And Working
The feature observes dataset quality, training results, evaluation slices, and deployment constraints, then returns a readiness score and prioritized fixes.
2.1 User Flow And Entry Points
| Screen | Function | Primary CTA | Alternate state | Completion condition |
|---|---|---|---|---|
| Dataset health | Shows missing labels, imbalance, duplicates, and split risk. | Fix dataset | Create baseline anyway | User accepts or repairs dataset issues. |
| Training summary | Explains model performance by class and error type. | View weak classes | Compare versions | User sees what failed and why. |
| Deployment readiness | Maps model quality to target environment. | Deploy with guardrails | Collect more data | Deployment decision is logged. |
2.2 Backend Decision Process
2.3 APIs And Responsibilities
| API / service | Responsibility | Inputs | Outputs | Owner |
|---|---|---|---|---|
POST /vision-readiness/scan | Dataset and annotation quality scan. | Dataset id, version id, task type. | Quality score, blockers, slices. | Dataset platform |
GET /vision-readiness/model | Model behavior explanation. | Train id, eval set, thresholds. | Weak classes, examples, risk score. | Training platform |
POST /vision-readiness/deploy | Deployment readiness decision. | Model id, target, latency, threshold. | Ready state, guardrails, monitor config. | Deploy platform |
2.4 Data Points, Edge Cases, And Terms
- Image metadata, label counts, split ids, class distribution.
- Evaluation metrics, confusion matrix, sample predictions.
- Deployment target, latency, confidence, endpoint telemetry.
- Small dataset: show low-confidence caveat.
- Rare class: require minimum examples before ready state.
- Edge device mismatch: recommend model/size change.
- Drift detected: trigger monitoring and retraining path.
- P0: deploy-ready shown for failing class.
- P1: readiness not updated after retraining.
- P2: incomplete fix explanation.
- Readiness score, weak slice, deployment target, guardrail threshold.
QA, Acceptance, And Validation Plan
QA must prove the advisor does not hide weak-class or deployment risk behind aggregate metrics. A model can have strong mAP and still fail in the specific class, camera angle, lighting condition, or edge environment the customer cares about.
3.1 UI And Flow QA
| Area | What QA must check | Expected standard | Severity |
|---|---|---|---|
| Dataset scanner | Imbalance, missing labels, duplicate images, corrupt images, class names, long project names, empty validation set. | Issues are grouped by severity with a clear repair path. | P1; P0 if blocker allows deploy-ready. |
| Model explanation | Weak classes, failure examples, confusion matrix, threshold impact, confidence distribution. | Aggregate metric never hides a critical weak slice. | P0 |
| Deployment CTA | Ready, warning, blocked, monitor-required, and retrain-required states. | CTA follows readiness decision and logs the decision path. | P0 |
| Responsive behavior | Tables, metric cards, examples, and charts across mobile/tablet/desktop. | Horizontal tables scroll cleanly on mobile; no clipped metric labels. | P1 |
3.2 API, Data, And Monitoring QA
| Layer | Validation needed | Negative tests | Monitoring |
|---|---|---|---|
| Quality scan | Matches fixture datasets and returns deterministic reason codes. | Missing labels, duplicate images, extreme class imbalance, data leakage. | Scan latency, blocker rates, reason-code drift. |
| Model evaluation | Class metrics, examples, and recommended thresholds are correct. | Bad threshold, weak minority class, overfit validation set, empty test split. | False-ready rate and eval recompute errors. |
| Deploy advisor | Target constraints are applied before ready state. | Edge latency failure, cloud API timeout, endpoint drift, low-confidence traffic. | Deployment rollback, drift alert precision, endpoint health. |
| Analytics | Readiness, fix, deploy, drift, and support events join by project/version/model. | Missing ids, duplicate events, stale model version, privacy-disabled telemetry. | Dashboard reconciliation and null-rate alerts. |
Release Plan
The advisor should launch first as a production-readiness review after training and before deployment, then move earlier into dataset upload and version creation once quality checks are calibrated.
4.1 Timeline
4.2 Release Criteria
| Area | Release standard | Evidence required | Blocker threshold |
|---|---|---|---|
| Functionality | Every project version gets dataset, model, and deployment readiness states. | Fixture projects for detection, segmentation, classification, cloud, and edge. | Missing state for deployable model. |
| Usability | User can identify top weak class, why it matters, and what to do next. | Usability pass with builders and operations users. | User deploys despite visible critical blocker. |
| Reliability | Readiness recomputes after dataset version, model retrain, or threshold change. | Versioning tests and event replay tests. | Stale readiness attached to new model. |
| Performance | Scanner and model analysis complete within acceptable wait for standard projects. | p95 scan/eval dashboards by dataset size. | Readiness blocks workflow without progress/fallback. |
| Supportability | Support can see the same project, version, reason codes, and recommended fix. | Support console smoke test. | Support cannot explain a readiness decision. |
| Compliance & Audit | Customer images, labels, examples, and model artifacts follow workspace permissions. | Permission tests and audit log review. | Private examples exposed outside authorized users. |
Gate 01
False-ready rate is zero on known bad projects.
Gate 02
Every blocker has a concrete fix or a safe escalation path.
Gate 03
Deployment readiness updates when threshold or target changes.
Gate 04
Readiness outcome joins cleanly to deployment health telemetry.
Data And Tools
Roboflow readiness depends on joined dataset, annotation, model, deployment, and telemetry data. Analytics must show whether the advisor moves teams from training to healthier production deployments.
5.1 Data Points And Joined Views
| View | Primary joins | Key fields | Decision it supports |
|---|---|---|---|
| Dataset health view | workspace_id, project_id, version_id | image_count, class_count, missing_labels, duplicates, class_balance, split_health | Which dataset issues block production readiness? |
| Model quality view | version_id, train_id, model_id | mAP, precision, recall, class metrics, confusion, example ids, threshold | Which classes or scenes need improvement? |
| Deployment readiness view | model_id, endpoint_id, target_type | target, latency, confidence, throughput, guardrail_state, monitor_required | Can this model run safely in its target environment? |
| Fix funnel view | project_id, version_id, readiness_id, event_session_id | fix_opened, relabel_clicked, retrain_started, deploy_clicked, monitor_enabled | Do users act on readiness recommendations? |
| Production health view | endpoint_id, model_id, project_id | drift_score, confidence_shift, latency, error_rate, rollback, alert_state | Did readiness predict stable deployment? |
5.2 Tools And Dashboarding
Use PostHog, Mixpanel, or Amplitude for readiness viewed, weak class opened, fix action clicked, retrain, deploy, monitor enabled, and rollback events.
Track weak-class frequency, false-ready projects, class imbalance, threshold changes, and post-deploy drift by project type.
Use Grafana, Datadog, or OpenTelemetry for scan latency, evaluation recompute, endpoint health, alert delivery, and monitor failures.
Connect readiness exposure to deploy conversion, project retention, paid plan conversion, support tickets, and production endpoint usage.
Success Metrics
Metrics must prove the advisor improves production readiness, not just training activity. A successful outcome is a model that users can deploy with clear risk, known weak spots, and ongoing monitoring.
Percentage of projects that pass readiness, deploy, and remain within quality, latency, and drift guardrails after launch.
| Metric group | Metric | Target | Why it matters | Guardrail |
|---|---|---|---|---|
| Activation | Readiness viewed → weak slice opened → fix or deploy decision | 45%+ | Users discover the advisor and engage with the diagnosis. | No increase in version abandonment. |
| Quality | Critical weak-class issue reduction before deployment | -30% | Advisor improves real model behavior, not just UI confidence. | No false deploy-ready state for critical weak class. |
| Deployment | Readiness-approved models that deploy successfully | +20% | Guidance should increase safe production rollout. | Rollback rate does not increase. |
| Reliability | Drift alert precision | 80%+ | Monitoring must be trusted by operations users. | No alert fatigue from noisy warnings. |
| Support | Quality-related support tickets per deployed model | -20% | Explanations should answer common model-quality questions. | No support spike from confusing states. |
| Business | Repeat project/version creation among exposed users | +15% | Users who trust the advisor should build more in Roboflow. | Usage growth remains tied to successful outcomes. |
Additional Details
7.1 Competitive Gap And How Roboflow Can Win
| Alternative | What users get today | Gap | Roboflow opportunity |
|---|---|---|---|
| Raw training notebooks | Flexible model training and custom eval. | Slow setup, expert-heavy debugging, weak productized deployment guidance. | Turn expert readiness review into a repeatable product flow. |
| Cloud vision APIs | Prebuilt inference with simple integration. | Less control over custom domain data and model behavior. | Custom model workflow with transparent readiness and fixes. |
| Generic MLOps tools | Experiment tracking and deployment infra. | Not optimized for annotation quality and vision-specific weak slices. | Own the vision-specific bridge from dataset to deployment. |
| Annotation-only tools | Labeling and review workflows. | Do not connect annotation quality to model and deployment outcome. | Close the loop from label issue to production impact. |
7.2 Responsibility Map
| Team | Ownership | Definition of done |
|---|---|---|
| Product | Readiness taxonomy, launch sequencing, metric scorecard, pilot scope, and risk tradeoffs. | Every release decision has a clear user value and guardrail. |
| Design | Readiness panel, weak-class drilldown, fix queue, deployment guardrails, mobile/tablet table behavior. | Users can understand weakness and action without reading raw confusion matrices. |
| Vision ML | Quality checks, weak-slice logic, threshold recommendations, drift indicators, fixtures. | Known bad datasets and models produce correct blocker states. |
| Platform engineering | APIs, event schemas, recompute jobs, version joins, permissions, and endpoint health telemetry. | Readiness is always attached to correct project/version/model. |
| Support + DevRel | Reason-code docs, customer examples, launch education, and support macros. | Support can explain any readiness state from logged evidence. |
Future Ideas And Roadmap
The roadmap should move from explainable readiness to automated fixes and then to continuous vision operations that keeps deployed models healthy after launch.
| Horizon | Idea | User value | Dependency | Risk |
|---|---|---|---|---|
| Near term | Reason-code docs and example gallery | Users learn why readiness blocked deployment. | Docs, examples, support macros. | Examples must not expose private data. |
| Near term | Threshold simulator | Shows precision/recall tradeoff before deployment. | Eval data and threshold service. | Users may optimize one metric too aggressively. |
| Medium term | Targeted data collection queue | Turns weak-slice findings into labeling tasks. | Annotation workflow and example retrieval. | Can overfocus on narrow slices. |
| Medium term | Deployment drift guardrails | Keeps model healthy after launch. | Endpoint telemetry and alerting. | Noisy alerts reduce trust. |
| Long term | Continuous vision ops advisor | Closes loop from production failure to retraining plan. | Monitoring, retraining, policy, and approval workflow. | Automated retraining needs strict governance. |