%20scale(0.100000%2C-0.100000)%22%0Astroke%3D%22none%22%3E%0A%3Cpath%20fill%3D%22%23000000%22%20d%3D%22M185%202691%20c-86%20-21%20-158%20-93%20-175%20-175%20-7%20-35%20-10%20-415%20-8%20-1196%203%0A-1276%20-2%20-1180%2073%20-1253%2020%20-20%2054%20-42%2074%20-49%2053%20-19%202349%20-19%202402%200%2020%207%2054%0A29%2074%2049%2075%2073%2070%20-23%2073%201253%202%20817%20-1%201161%20-9%201200%20-9%2046%20-19%2063%20-64%20106%0A-42%2041%20-63%2054%20-104%2063%20-59%2013%20-2284%2014%20-2336%202z%20m786%20-547%20l314%20-255%203%20255%202%0A256%2060%200%2060%200%202%20-255%203%20-256%20315%20257%20315%20257%203%20-292%202%20-291%20135%200%20135%200%200%0A-450%200%20-450%20-135%200%20-135%200%20-2%20-296%20-3%20-295%20-312%20275%20c-172%20152%20-315%20276%20-318%0A276%20-3%200%20-5%20-133%20-5%20-295%20l0%20-295%20-60%200%20-60%200%200%20295%20c0%20162%20-2%20295%20-5%20295%20-3%0A0%20-146%20-124%20-318%20-276%20l-312%20-276%20-3%20296%20-2%20296%20-135%200%20-135%200%200%20450%200%20450%0A135%200%20135%200%200%20290%20c0%20160%202%20290%204%20290%202%200%20145%20-115%20317%20-256z%22%2F%3E%0A%3Cpath%20fill%3D%22%23FFFFFF%22%20d%3D%22M971%202144%20l314%20-255%203%20255%202%0A256%2060%200%2060%200%202%20-255%203%20-256%20315%20257%20315%20257%203%20-292%202%20-291%20135%200%20135%200%200%0A-450%200%20-450%20-135%200%20-135%200%20-2%20-296%20-3%20-295%20-312%20275%20c-172%20152%20-315%20276%20-318%0A276%20-3%200%20-5%20-133%20-5%20-295%20l0%20-295%20-60%200%20-60%200%200%20295%20c0%20162%20-2%20295%20-5%20295%20-3%0A0%20-146%20-124%20-318%20-276%20l-312%20-276%20-3%20296%20-2%20296%20-135%200%20-135%200%200%20450%200%20450%0A135%200%20135%200%200%20290%20c0%20160%202%20290%204%20290%202%200%20145%20-115%20317%20-256z%22%2F%3E%0A%3Cpath%20fill%3D%22%23000000%22%20d%3D%22M780%201981%20l0%20-161%20215%200%20216%200%20-203%20151%20c-112%2084%20-209%20156%20-215%20162%0A-10%207%20-13%20-24%20-13%20-152z%22%2F%3E%0A%3Cpath%20fill%3D%22%23000000%22%20d%3D%22M1706%201982%20l-210%20-157%20209%20-3%20c114%20-1%20210%20-1%20212%201%202%202%202%2074%201%20160%0Al-3%20156%20-209%20-157z%22%2F%3E%0A%3Cpath%20fill%3D%22%23000000%22%20d%3D%22M510%201370%20l0%20-330%2070%200%2070%200%200%2088%200%2088%2038%2035%20c20%2020%20146%20127%20280%20239%0A133%20111%20242%20204%20242%20206%200%202%20-157%204%20-350%204%20l-350%200%200%20-330z%22%2F%3E%0A%3Cpath%20fill%3D%22%23000000%22%20d%3D%22M1490%201696%20c0%20-2%20126%20-102%20280%20-223%20l280%20-218%200%20-107%200%20-108%2070%200%2070%0A0%200%20330%200%20330%20-350%200%20c-192%200%20-350%20-2%20-350%20-4z%22%2F%3E%0A%3Cpath%20fill%3D%22%23000000%22%20d%3D%22M1028%201392%20l-247%20-217%200%20-283%20c-1%20-233%201%20-282%2012%20-275%208%204%20122%20104%0A255%20222%20l242%20214%200%20278%20c0%20154%20-3%20279%20-7%20279%20-5%200%20-119%20-98%20-255%20-218z%22%2F%3E%0A%3Cpath%20fill%3D%22%23000000%22%20d%3D%22M1410%201332%20l0%20-279%20242%20-214%20c133%20-118%20247%20-218%20255%20-222%2011%20-7%2013%0A42%2012%20275%20l0%20283%20-245%20215%20c-135%20118%20-249%20217%20-254%20218%20-6%202%20-10%20-101%20-10%0A-276z%22%2F%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E%0A)
Perplexity SonarTearDown
About Sonar
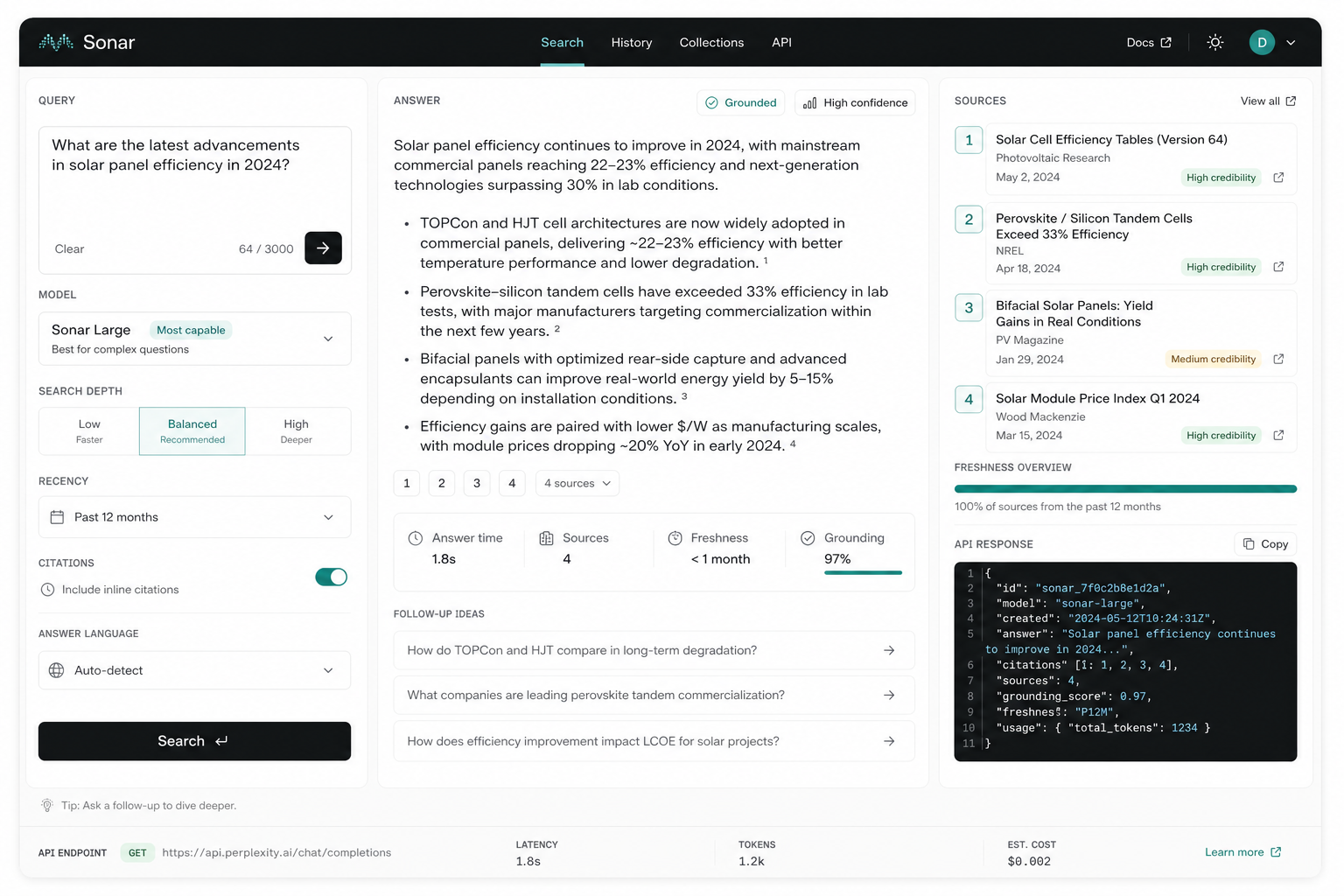
Perplexity Sonar provides web-grounded AI responses and search capabilities for developers building products that need current answers, citations, streaming, and retrieval control. The teardown studies how AI search shifts UX from links to answer-plus-sources, and where trust can break.
Business Signal
Product insight: as AI builders move from demos to deployed workflows, the core product value shifts from access to confidence, readiness, and explainability.
Problem Discovery
The highest-value problem is not simply "users want answers instead of links." The product problem is that developers and end users need to know whether a generated answer is current, source-grounded, and safe to act on.
Users see citations but may not know source freshness, conflict, coverage, or whether the answer overstates evidence.
A cited answer still requires mental work to judge if the response is complete, current, and aligned with source context.
If developers cannot explain answer reliability, they may use raw search APIs, RAG stacks, or manual review instead.
PM QuestionHow might Sonar make answer trust inspectable so users can act faster without blindly trusting a generated response?
User Personas
The teardown compares four AI-search users, then focuses on Arjun because he represents the developer buyer who must expose Sonar output inside a user-facing product.

Riya Mehta
Research Analyst- Age / City
- 29, Bengaluru
- Skill
- Intermediate
- Need
- Market scan with citations
- Pain
- Needs source comparison

Arjun Rao
AI Product Engineer- Age / City
- 31, Mumbai
- Skill
- Beginner
- Need
- Builds cited answer feature
- Pain
- Needs explainable trust signals

Neha Kapoor
Product Lead- Age / City
- 26, Delhi
- Skill
- Advanced beginner
- Need
- Enterprise knowledge assistant
- Pain
- Needs reliability guardrails

Kabir Singh
News App Founder- Age / City
- 34, Pune
- Skill
- Target user
- Need
- Real-time answer feed
- Pain
- Needs freshness and source controls
Arjun Rao, AI product engineer
Arjun is the best teardown lens because he must turn Sonar output into a product experience. He needs answer quality, citation trust, freshness, and failure states to be explainable to his users.
User Journey Map
The journey breaks when a fast answer is not clearly safe to trust. The user needs source quality, freshness, and uncertainty signals before acting on the response.
Finds Sonar as a way to build a cited answer experience inside a product.
🙂 CuriousKnows users want fast answers, but not how much trust context to expose.
Show answer examples with freshness, source coverage, and confidence states.
Tests queries across current events, product docs, and ambiguous topics.
🤔 UnsureDoes not know when sources are fresh, conflicting, or thin.
Add source freshness and citation coverage diagnostics.
Chooses model, search mode, recency, domain, and citation policy.
😟 CautiousLatency, cost, freshness, and trust tradeoffs are difficult to compare.
Show trust-policy preview and expected latency/cost.
Ships answer experience to a pilot cohort.
😬 AnxiousLow visibility into source quality and answer uncertainty.
Expose trust badge, evidence drawer, and fallback state.
Users challenge answer quality or citation relevance.
😞 FrustratedTrust issue appears after the answer has already been shown.
Offer contradiction detection and low-confidence fallback.
Reviews evidence trail and trust reasons.
🙂 RelievedNeeds to know which source or policy caused low trust.
Rank trust improvements by coverage, freshness, and risk.
Expands cited-answer feature to more workflows.
😊 ConfidentNeeds monitoring for stale or contradicted answers.
Add source drift monitoring and answer audit trail.
Tunes trust policy and query coverage.
🙂 FocusedNeeds eval history across answer categories.
Provide eval dashboard and next-best trust improvement.
Pain Prioritization
Before choosing a solution, the teardown compares the strongest pain points and uses RICE to identify which problem deserves the first product bet.
Users see citations but still need to inspect too much manually.
Users cannot quickly tell if the answer used current enough sources.
Users need answer confidence, source coverage, conflict markers, and fallback states.
| Pain point | Reach | Impact | Confidence | Effort | RICE |
|---|---|---|---|---|---|
| Citation overload | 4 | 4 | 4 | 2 | |
| Freshness ambiguity | 3 | 5 | 3 | 3 | |
| Trust state is unclear | 5 | 5 | 4 | 2 |
Decision: prioritize the clarity/readiness gap because it has the strongest reach-to-effort ratio and can be improved through product guidance before deeper platform changes.
Recommended Solution
Ideas are split by execution ambition first. The final prioritization is applied only to Moonshot ideas because those are the strategic bets that need a clear PM decision framework.
OK Ideas
Best Ideas
Moonshot Ideas
Solution Prioritization
Solution Discussion
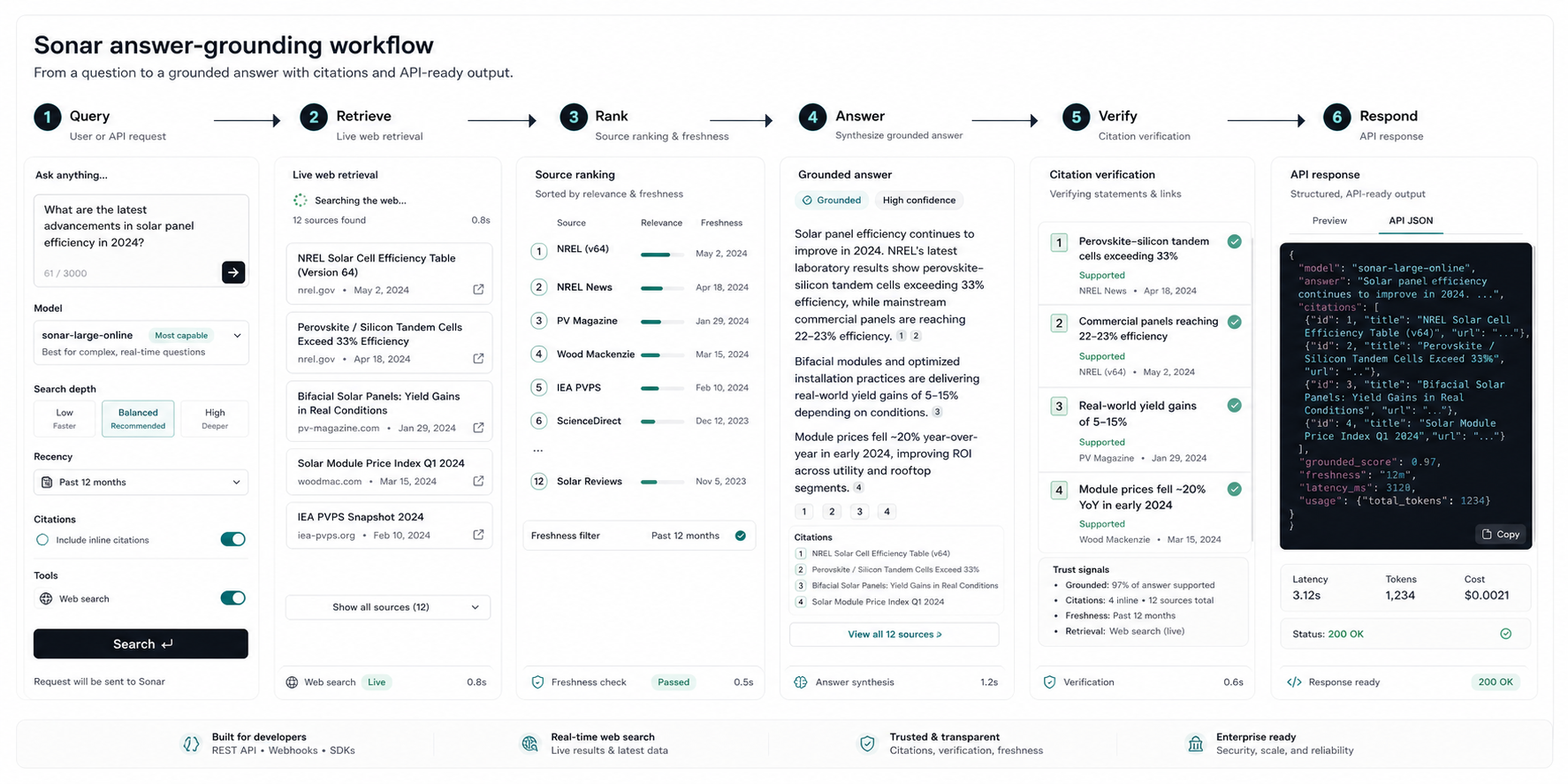
Selected solution: Autonomous answer trust layer. The product should make the hidden AI/system decision visible before users commit time, money, or trust.
A trust layer that turns retrieval quality, source freshness, source diversity, citation coverage, and answer uncertainty into visible product states.
- Inspect
Read query intent, source set, recency, citation spans, domain policy, and answer uncertainty.
Data contract: query_id, retrieval_set, freshness_window, citation_spans. - Score
Classify answer trust, source coverage, conflict risk, and fallback state before surfacing.
Decision contract: trust_state, reason_codes, source_quality, confidence. - Guide
Show trust badge, evidence drawer, source reasons, and action CTA only when guardrails pass.
UI contract: trust card, evidence drawer, conflict badge, fallback CTA. - Learn
Compare answer feedback, citation opens, trust failures, and source drift by query class.
Feedback loop: answer evals, source freshness, user corrections.
Dashboard card, explanation drawer, readiness state, recommended action, and safe launch CTA.
- Status badge
- Reason drawer
- Next action
Feature extraction, scoring service, reason-code mapper, recommendation engine, and audit log.
- Policy engine
- Signal store
- Audit trail
Cost, quality, accuracy, data, and user-trust guardrails before surfacing a confident CTA.
- Confidence checks
- Fallback state
- Logs
Higher successful completion, lower failed attempts, lower support dependency, and stronger retention.
- 10% pilot
- Quality guardrail
- Retention lift
Implementation Plan
Launch as a controlled pilot: build explainable trust decisions first, then expose them through developer UI, SDK examples, and monitoring surfaces.
Capture query intent, retrieval context, source metadata, and domain policy.
Convert retrieval signals into trust state and reason codes.
Surface confidence, source coverage, conflict state, and safe next action.
Track outcome and learn from failures.
Retrieval metadata, source scorer, citation-span validator, trust score.
Owner: Product + EngineeringTrust badge, evidence drawer, source quality labels, fallback states.
Owner: Product + DesignAnswer eval set, contradiction taxonomy, source drift alerts, review playbooks.
Owner: Product + OpsFinalize trust states, source signals, and decision contract.
Trust API, evidence UI states, and event tracking.
Backtest answer trust decisions and review source-copy language.
Launch to controlled developer cohort with answer-quality guardrails.
Expand after grounding quality, adoption, and retention checks.
Quality: trust logic matches expert review.
Product: fewer low-trust answers and lower manual verification dependency.
Business: higher grounded-answer completion and repeat API usage.
Success Metrics
Metrics must prove Sonar improves answer trust, action confidence, and source-grounded completion without increasing hallucination risk or citation misuse.
Percentage of answer sessions where users inspect trust signals, accept or act on a grounded answer, and remain within freshness, citation, and confidence guardrails.
Trust badge viewed → evidence drawer opened → answer action started
>35%Shows users notice and understand the trust layer.
Low confusion and low support escalation.
Grounded answer accepted or cited successfully
20-30%Measures whether trust signals convert into confident answer usage.
Quality pass rate stays high.
Answer passes source-grounding and freshness threshold
>80%Prevents growth from becoming low-quality usage.
No increase in hallucinated, stale, or contradicted answers.
Repeat API usage, retention, expansion, lower search-stack switching
>70%Confirms the product keeps developers building on Sonar.
Revenue grows without trust deterioration.
GTM
Launch should start with developers already building answer-plus-source experiences, not broad AI-search awareness. The motion is product-triggered, guidance-led, and guarded by quality checks.
Developers with clear answer-trust requirements and measurable grounded-answer completion.
Show guidance when an answer has source freshness, coverage, or contradiction risk.
Dashboard cards, docs examples, templates, email nudges, and support scripts.
Limit rollout by success rate, quality threshold, and support impact.
Budget Allocation
Run trust scoring without changing the answer flow.
Expose trust badge and evidence drawer to a controlled developer cohort.
Trigger answer action only when trust guardrails pass.
Expand by success, trust, and retention checks.
Summary
The teardown identifies a high-value AI product clarity gap and turns it into a prioritized solution, rollout plan, metrics system, and GTM motion.
Users need confidence before acting on generated answers.
The selected user proves the issue is answer trust, not only search capability.
A trust layer that turns retrieval quality, source freshness, source diversity, citation coverage, and answer uncertainty into visible product states.
Build trust scoring service, evidence UI, answer-quality guardrails, and monitoring loop.
Sonar should not only return answer plus sources. The product opportunity is to make answer trust inspectable through freshness, coverage, conflict, and fallback states so users can act with confidence.