About Product
1.1 What We Are Making
Perplexity Sonar Answer Trust Layer is a developer-facing trust, verification, and observability layer for Sonar API responses. It helps teams building AI search experiences understand whether an answer is current, well-sourced, claim-supported, policy-compliant, and safe to render to an end user. The product does not only return citations; it explains how strongly each important answer claim is supported by retrieved sources.
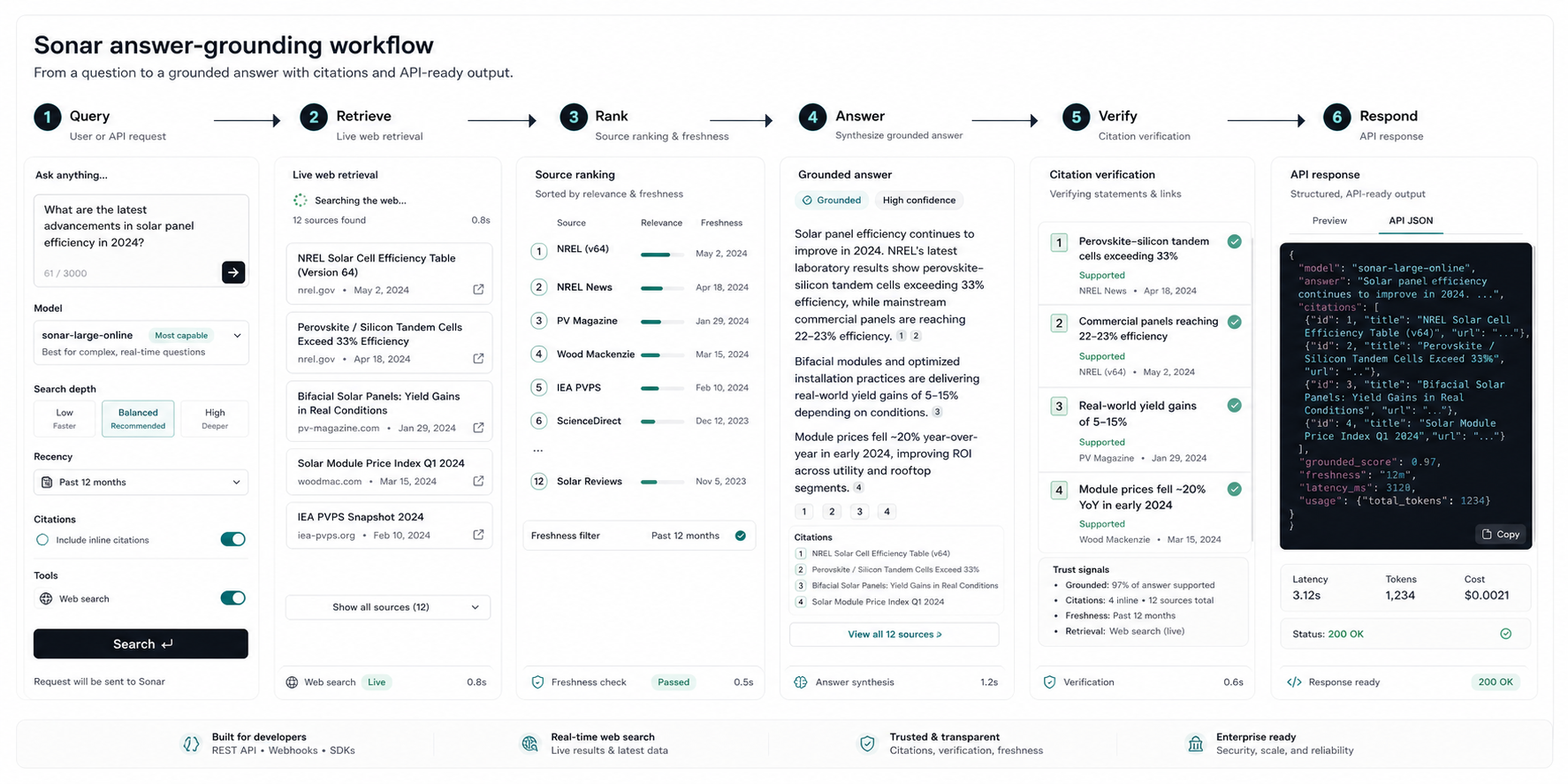
Perplexity Sonar Answer Trust Layer.
AI search API trust, retrieval observability, citation verification, answer governance, and developer tooling.
- Claim-to-citation support map for important answer statements.
- Source freshness, relevance, authority, and diversity scoring.
- Unsupported claim, stale source, low-confidence, and contradiction warnings.
- Developer trace console for retrieval, ranking, generation, verification, latency, and cost.
- API policy controls for citation strictness, freshness window, blocked domains, fallback behavior, and trace retention.
- Helps developers debug answer quality before users see weak output.
- Reduces hallucination and source-mismatch risk in answer-plus-sources UX.
- Creates production confidence for current-events, research, finance, support, and enterprise knowledge flows.
- Differentiates Sonar from generic LLM APIs by making grounding measurable and tunable.
AI search changes the interface from a list of links to a direct answer. Once the answer is the product, developers need proof that the response is grounded, current, source-supported, and auditable. A citation list is not enough if the product cannot tell which citation supports which claim.
Give every Sonar developer a clear trust object and debugging workflow so they can decide when to render, warn, retry, narrow, or suppress an answer without building trust infrastructure from scratch.
1.2 Who It Is For
The feature targets teams that use Sonar to power answer experiences in production. These users care about speed, but they cannot ship confidently unless they can inspect source quality and claim support.
| User cohort | Description | How they use it | Primary product promise |
|---|---|---|---|
| AI app developers | Engineers building answer UX, copilots, research tools, support bots, or vertical search products. | Send API request, inspect trust object, configure strictness, and decide how to render answer state. | Know whether answer claims are supported enough for the user experience. |
| Enterprise platform teams | Teams deploying Sonar behind governed internal search, knowledge, compliance, or customer-support workflows. | Set allowed domains, freshness rules, trace retention, fallback policy, and audit exports. | Make answer generation auditable, policy-aware, and safe for enterprise use. |
| Search/product teams | PMs and search engineers measuring answer quality, low-trust topics, and source experience performance. | Use dashboards to find unsupported claims, stale domains, weak retrieval queries, and high-fallback topics. | Improve answer quality without guessing where retrieval or generation failed. |
1.3 Why We Are Building It
Background
Sonar's core value is web-grounded answer generation. The product gap appears after the first successful integration: teams need to understand answer reliability, source selection, and failure modes at scale. If developers cannot debug weak answers, they either over-filter results, add manual review, or switch to less ambitious link-based experiences.
Assumptions
- Developers will pay attention to trust metadata if it directly maps to render/fallback decisions.
- Claim-level citation mapping is more useful than a generic source list for production debugging.
- Freshness and contradiction warnings are critical for topics where outdated information creates user harm.
- Policy controls must be simple enough for default usage but configurable enough for enterprise teams.
- Trace retention and privacy must be configurable because many customers send sensitive or proprietary queries.
Market Opportunity
AI search is moving from consumer answer pages into developer APIs, vertical products, enterprise workflows, research assistants, and support automation. The teams most likely to become large customers need production trust infrastructure, not only a high-quality answer endpoint.
Company Goals Alignment
- Developer adoption: reduce integration risk and shorten time from demo to production.
- Enterprise readiness: support audit trails, source policies, and governance requirements.
- Usage growth: increase production request volume by giving teams confidence to render answers.
- Brand trust: reinforce Perplexity's position around cited, source-aware AI search.
Feature Architecture And Working
The feature has two linked layers: trust metadata returned in the API response, and a developer console that explains how retrieval, ranking, generation, verification, and policy handling produced that response.
2.1 Developer Flow And Entry Points
| Surface | Function | Primary CTA | Alternate state | Completion condition |
|---|---|---|---|---|
| API response | Returns answer, citations, trust object, warning set, trace id, and policy decision. | Render answer | Render warning, retry, or fallback | Client app can make a deterministic display decision. |
| Trace console | Shows query, retrieved candidates, source ranking, claim map, verification result, latency, and cost. | Inspect weak claim | Compare another request | Developer can explain why answer passed or failed trust checks. |
| Policy settings | Configures strictness, freshness, blocked/allowed domains, source count, fallback behavior, and retention. | Save policy | Preview before applying | New policy version is active and attached to future responses. |
| Trust dashboard | Aggregates unsupported claims, stale source rate, contradiction rate, fallback rate, and topic clusters. | Open trace cluster | Export logs | Team identifies quality issue and creates fix or policy change. |
2.2 Backend Decision Process
2.3 Backend APIs And Responsibilities
| API / service | Responsibility | Inputs | Outputs | Owner |
|---|---|---|---|---|
POST /sonar/query |
Primary answer generation endpoint with trust metadata. | query, model, citation_policy_id, freshness_window, trace_mode, user_context. | answer, citations, trust_score, warnings, claim_map, trace_id, policy_version. | Sonar API platform |
GET /sonar/traces/{trace_id} |
Returns request trace for debugging and audit. | trace_id, org_id, user permissions, retention state. | query intent, retrieval candidates, ranking scores, claim map, warnings, latency, cost. | Developer platform |
POST /sonar/policies |
Creates or updates trust policy configuration. | strictness, freshness, blocked_domains, allowed_domains, fallback_threshold, retention_days. | policy_id, policy_version, validation result, preview impact. | Enterprise platform |
POST /sonar/verify |
Verifies answer and citations for a generated or customer-provided response. | answer text, sources, claim extraction mode, target strictness. | claim_support_map, unsupported_claims, contradiction warnings, confidence score. | Trust quality service |
POST /sonar/events |
Tracks developer console usage, policy changes, render decisions, and feedback. | trace_id, app_id, action, render_state, feedback, policy_version. | event_id, dashboard attribution, experiment tag. | Data platform |
2.4 Data Points, Edge Cases, And Developer Terms
- Query id, trace id, app id, org id, model, policy id, policy version, strictness level.
- Source URL, title, domain, snippet, freshness, rank score, authority score, retrieval timestamp.
- Claim id, claim text, citation ids, support confidence, contradiction flag, unsupported flag.
- Latency, token usage, request cost, fallback state, developer feedback, end-user feedback.
- No sources found: return no-answer state with suggested query narrowing.
- Stale sources only: return answer with freshness warning or suppress based on policy.
- Conflicting sources: show contradiction warning and avoid single definitive answer.
- Blocked domain dominates result: remove source and re-rank; if evidence weak, fallback.
- Trace retention expired: preserve aggregate metadata but hide raw query/source payload.
- P0: high-confidence answer contains unsupported or contradicted critical claim.
- P0: policy says suppress, but API returns renderable answer.
- P1: trace missing for production request with trust warning.
- P1: source freshness or blocked-domain policy not applied.
- P2: dashboard mismatch, copy polish, non-critical console layout issue.
- Trust score: response-level score combining source quality, claim support, freshness, and policy.
- Claim map: mapping between answer claims and citation evidence.
- Citation strictness: policy controlling required support before answer can be rendered.
- Fallback threshold: score or warning condition that triggers no-answer or retry behavior.
QA, Acceptance, And Validation Plan
QA must prove that the trust object is accurate, traceable, and useful. The release should be blocked if Sonar marks unsupported claims as strongly supported, loses traces, ignores policy, or creates a misleading safe-to-render state.
3.1 UI, Console, And Developer Flow QA
| Area | What QA must check | Expected standard | Severity |
|---|---|---|---|
| Trace viewer | Query, retrieved sources, rank scores, claim map, warnings, latency, token use, and policy version. | Developer can identify whether failure happened in retrieval, ranking, generation, verification, or policy. | P1, P0 if trace missing for warned production response. |
| Claim support table | Claim text, citation ids, support score, unsupported labels, contradiction labels, and hidden overflow. | No claim is marked supported unless citation evidence directly supports it. | P0 if unsupported critical claim appears supported. |
| Policy editor | Strictness slider, freshness window, domain controls, fallback threshold, retention settings, preview impact. | Policy changes are previewed, versioned, saved, and attached to future responses. | P0 if saved policy does not apply. |
| Dashboard | Low-trust topics, fallback rate, stale-source rate, unsupported-claim rate, trace open rate, export. | Teams can find the highest-risk query clusters without manually reading logs. | P1 if dashboard numbers cannot reconcile with API logs. |
| Responsive behavior | Console tables, long URLs, long claims, source cards, mobile and tablet rendering. | No critical trace field, warning, or policy control is clipped or hidden. | P1, P0 if policy save or warning visibility breaks. |
3.2 API, Data, Analytics, And Audit QA
| Layer | Validation needed | Negative tests | Monitoring signal |
|---|---|---|---|
| Query API | Trust object, warnings, citations, claim map, trace id, policy version return consistently. | Ambiguous query, no source, stale source, blocked domain, high-sensitivity topic, timeout. | Trust object missing rate, fallback rate, warning rate, p95 latency. |
| Claim verifier | Claim extraction and citation support match fixture expectations. | Unsupported claim, source contradiction, citation only supports partial claim, source has outdated date. | False-supported rate, false-unsupported rate, contradiction miss rate. |
| Trace API | Trace data is permissioned, retained correctly, and complete for debuggable responses. | Expired trace, unauthorized org, partial retrieval, redacted query, retention disabled. | Trace availability, authorization failure, trace completeness. |
| Policy engine | Strictness, freshness, domain rules, fallback, and retention are applied in correct order. | Blocked source is top result, strict policy with weak evidence, freshness window mismatch. | Policy mismatch count, blocked-domain leakage, stale-source leakage. |
| Events | Each trace open, warning click, policy edit, render decision, user feedback, and retry is tracked. | Offline console, duplicate feedback, API retry, session timeout, policy preview without save. | Event drop rate, duplicate rate, dashboard reconciliation mismatch. |
| Audit log | Every trust decision has query id, trace id, model, policy version, source set, and verification result. | Missing trace id, retention redaction, policy rollback, source removed after response. | Audit completeness, export success, lineage mismatch. |
- Unsupported claim receives high support confidence.
- Blocked domain appears in citation list after policy application.
- Freshness policy is ignored for current-events queries.
- API returns answer without trace id when trace mode is required.
- Simple factual query with strong citations.
- Ambiguous query with conflicting sources.
- Freshness-sensitive query with stale high-ranking sources.
- Policy test with blocked domain, strict mode, and no-answer fallback.
Release Plan
Release must be phased because the feature changes what developers trust in production. The first release should focus on observability and safe defaults; later releases can expose stronger policy automation and continuous evaluation.
4.1 Timeline
4.2 Release Criteria
| Criteria | Requirement | Evidence required | Blocker |
|---|---|---|---|
| Functionality | API returns trust score, warning set, claim map, citations, trace id, policy version, and fallback decision. | Passed contract tests across supported, partial, unsafe, stale, contradictory, and no-source states. | P0/P1 defects in trust object or fallback logic. |
| Usability | Developers can understand why an answer passed or failed trust checks within the trace console. | Developer UAT, docs review, trace task completion, no clipped tables or hidden warnings. | Trace is present but not actionable. |
| Reliability | Timeouts, source fetch failures, verification failures, and trace persistence failures fail safely. | Failure injection, fallback tests, retry tests, monitoring dashboards. | Unsafe answer can render during degraded verification. |
| Performance | Trust checks do not push API latency beyond customer-acceptable threshold for standard mode. | p50/p95 latency, cost, token, and trace persistence benchmarks. | Latency breaks production app experience. |
| Supportability | Support and devrel can inspect trace id, policy version, warning state, and response lineage. | Support playbook, issue tags, customer debug workflow, escalation path. | Customer issue cannot be traced or explained. |
| Compliance + audit | Trace retention, query redaction, source storage, and org permissions follow customer policy. | Security review, retention tests, export tests, permission tests. | Cross-org trace exposure or retention violation. |
| Dependencies | Retrieval logs, ranking scores, source metadata, verifier, policy engine, and event pipeline are stable. | Dependency checklist and fallback behavior approved. | Critical dependency has no owner or safe fallback. |
Data And Tools
This section defines the data needed to operate the product, analyze adoption, monitor trust quality, and help developers debug. The feature should not ship unless dashboards can explain whether it improves answer trust without creating unacceptable latency, cost, or no-answer behavior.
5.1 Data Points And Joined Views
| Joined view | Source tables / systems | Key fields | Analytics purpose |
|---|---|---|---|
| API request trust view | API gateway, model service, verifier, policy engine. | request_id, trace_id, app_id, model, policy_version, trust_score, warning_count. | Measure trust quality and response behavior by app, model, policy, and query type. |
| Source quality view | Retrieval service, ranking service, source metadata, web index. | source_url, domain, freshness, rank_score, authority_score, citation_count, contradiction_flag. | Find stale domains, low-quality source clusters, and ranking failure patterns. |
| Claim support view | Claim extractor, citation verifier, answer generator. | claim_id, trace_id, claim_text_hash, support_state, citation_ids, confidence, warning_type. | Measure unsupported claim rates and verifier quality. |
| Developer adoption view | Console events, SDK usage, API requests, policy settings. | trace_opened, policy_saved, warning_clicked, retry_created, render_state, app_id. | Understand whether developers use trust features and where they get stuck. |
| Business outcome view | Billing, API usage, support, enterprise accounts, feedback. | request_volume, production_flag, retention, support_ticket_count, expansion_flag. | Connect trust-layer usage to production adoption and revenue signals. |
5.2 Tools And Dashboarding
- Use PostHog, Mixpanel, or Amplitude for console usage, trace opens, warning clicks, and policy changes.
- Track app_id, org_id, trace_id, trust_state, warning_type, policy_version, and SDK version.
- Build funnels for first API call to trace inspection to policy save to production traffic.
- Use Looker, Metabase, Tableau, or Superset for weekly product, quality, and enterprise dashboards.
- Join API requests, trust scores, source quality, claim support, support tickets, and billing data.
- Dashboard tabs: adoption, trust quality, source health, policy usage, reliability, business impact.
- Use Datadog, Grafana, or OpenTelemetry for API latency, verifier latency, trace persistence, and errors.
- Alert on trust-object missing, source policy mismatch, verification timeout, and trace write failure.
- Track p50/p95/p99 latency by standard mode, strict mode, and trace mode.
- Maintain golden query sets for factual, freshness-sensitive, ambiguous, contradiction, and no-source cases.
- Run scheduled evals for claim support precision, fallback appropriateness, and source freshness handling.
- Use human review on sampled high-risk traces to calibrate verifier and ranking behavior.
Success Metrics
Percentage of production Sonar responses that pass configured trust policy, have sufficient claim support, use acceptable source freshness, and are rendered without developer override or end-user quality complaint.
| Metric group | Metric | Expected signal | Why it matters |
|---|---|---|---|
| Activation | First API call to trace open rate | 30%+ among new production-intent developers. | Shows whether developers notice and use the trust workflow. |
| Configuration | Trace open to policy save rate | Meaningful adoption for apps with repeated production traffic. | Confirms trust layer is actionable, not only informational. |
| Quality | Unsupported high-confidence claim rate | 40% reduction vs baseline evaluator. | Prevents the highest-risk trust failure. |
| Freshness | Stale-source render rate for freshness-sensitive topics | Downward trend after freshness policy launch. | Current information is core to AI search trust. |
| Reliability | Trace availability and trust-object completeness | Near-zero missing trace for trace-enabled production responses. | Customers cannot debug or audit without lineage. |
| Performance | Latency overhead from verification | Within agreed budget for standard mode and strict mode. | Trust cannot make API unusably slow. |
| Business | Production API retention and request growth for trust-layer users | Positive lift vs non-trust-layer cohort. | Measures whether trust improves real developer adoption. |
| Support | Answer-quality support tickets per production app | Reduction after trace console and policy controls launch. | Confirms developers can self-debug more issues. |
Additional Details
This section covers competitive positioning, cross-functional ownership, and implementation responsibilities required before an engineering team can build the feature from the PRD.
7.1 Competitive Gap And How Sonar Can Win
| Competitor pattern | Observed gap | Sonar opportunity | Product response |
|---|---|---|---|
| Generic LLM APIs | High fluency but weak source grounding and little claim-level explainability. | Win teams that need current, sourced answers rather than pure generation. | Claim map, source scores, and no-answer fallback when evidence is weak. |
| Search APIs | Return links/snippets but leave answer synthesis and trust logic to the developer. | Offer answer plus evidence plus trust metadata in one API contract. | Unified response object with answer, citations, trust, and trace. |
| Enterprise RAG stacks | Powerful but expensive to build, maintain, evaluate, and govern. | Provide managed answer-grounding controls for teams without full RAG infrastructure. | Policy controls, dashboard, eval-ready traces, and SDK support. |
| Consumer AI search | Good UX but not enough API-level observability for production apps. | Make Perplexity's answer trust legible to developers and enterprise buyers. | Developer console, audit exports, and production dashboards. |
7.2 Responsibility Map
| Team | Responsibility | Key deliverables | Definition of done |
|---|---|---|---|
| Product | Own trust schema, policy knobs, metrics, developer workflow, release sequencing. | PRD, state model, response contract, metric definitions, release memo. | All teams understand what the trust layer promises and what it does not guarantee. |
| Design | Own trace console, claim map, source cards, policy editor, warning hierarchy, and dashboard IA. | Responsive console screens, table states, warning copy, empty/error states. | Developers can inspect trust failure without reading raw logs. |
| API engineering | Own API contract, SDK types, trace id propagation, policy application, and backward compatibility. | Endpoints, typed response objects, SDK updates, migration docs, contract tests. | Existing users are not broken and new trust object is stable. |
| Search quality | Own retrieval/ranking quality, source scoring, freshness handling, and golden eval sets. | Eval suite, source score model, freshness classifier, ranking diagnostics. | Trust warnings reflect real retrieval quality issues. |
| Trust + safety | Own warning taxonomy, sensitive topic policy, blocked domains, and fallback standards. | Policy review, red-team test set, high-risk topic handling, escalation path. | High-risk answers fail safely under configured policy. |
| Data + DevRel | Own dashboards, customer readouts, docs examples, SDK guides, and feedback loops. | Analytics spec, dashboards, docs, examples, customer beta report. | Customers can adopt and debug the feature without custom support. |
Future Ideas And Roadmap
V1 should make answer trust inspectable. Future versions can move from passive trust metadata to active policy automation, continuous evaluation, and customer-specific trust models.
| Roadmap phase | Idea | Why it matters | Dependency | Risk |
|---|---|---|---|---|
| V1.1 | SDK trust helpers | Developers can render supported, warned, and fallback states faster. | Stable trust object and framework examples. | Over-opinionated defaults may not fit every product. |
| V1.2 | Trace export and audit packet | Enterprise teams can share evidence with compliance, support, and internal stakeholders. | Retention controls, permission model, export format. | Privacy leakage if raw query/source payload is mishandled. |
| V1.3 | Trust benchmark suite | Customers can test Sonar against their common query patterns before launch. | Eval harness, golden query upload, scoring report. | Benchmark may be misread as universal accuracy guarantee. |
| V2 | Customer source policy templates | Teams can choose policies for research, finance, support, health, or internal knowledge workflows. | Policy engine, domain metadata, vertical templates. | Policy complexity may overwhelm small developers. |
| V2 | Low-trust query clustering | Product teams can find repeated failure themes instead of debugging individual requests. | Query clustering, privacy-safe aggregation, dashboard drill-down. | Clusters may expose sensitive query patterns if permissions are weak. |
| Moonshot | Autonomous answer QA agent | Continuously tests production queries, detects trust regressions, and recommends policy or prompt fixes. | Eval infrastructure, customer-specific policies, scheduled tests, alerting. | Automated policy suggestions need strong review controls. |