DataTalk
Project tier down for natural-language querying over company data using constrained intent/slot compilation and an experimental SLM training path.
Concept
Business teams cannot reliably answer data questions without SQL or analyst support.
Product, sales, risk, and operations teams often need fast answers from company data, but they do not know table names, joins, filters, or schema relationships. Generic AI can produce confident but unverified answers, while dashboards only cover fixed questions. DataTalk solves this by turning natural-language questions into schema-aware, SQL-backed, source-row verified answers.

User Personas
| Age | 32 |
|---|---|
| Experience | 7 years in B2B SaaS product management and analytics workflows. |
| Behaviour | Asks cross-functional questions across product, sales, support, billing, and risk data. |
| Pain Points | Does not know table names or relationships, waits on analysts, and needs fast validation. |
| Age | 35 |
|---|---|
| Experience | 9 years in operational risk, audit reporting, compliance checks, and exception analysis. |
| Behaviour | Reviews suspicious accounts, invoices, support tickets, churn signals, and customer risk patterns. |
| Pain Points | Manual checks are slow, joins are complex, and audit work needs traceable source rows. |
| Age | 29 |
|---|---|
| Experience | 6 years in enterprise sales, customer growth, and revenue operations. |
| Behaviour | Looks for high-value customers, regional performance, revenue, overdue invoices, and account health. |
| Pain Points | Depends on RevOps, dashboard filters are limited, and customer signals are hard to connect. |
Selected User Persona
Riya Shah, Product Manager
Riya is the strongest starting persona because Product Managers sit between product, sales, support, billing, and leadership. Her workflow naturally tests cross-functional data needs, high follow-up frequency, answer trust, and demo clarity in one user journey.
User Journey Map
| Journey Stage | Actions | Emotion With Emoji | Pain Points | Opportunities |
|---|---|---|---|---|
| Frame Business Question | Riya starts with a business question in plain language instead of SQL. | Curious 🤔 | She does not know the exact table names, columns, or relationships. | Let the user ask questions without needing schema knowledge. |
| Check Schema And Data | She tries to understand which tables contain product, sales, support, or billing signals. | Confused 😕 | Table relationships are hard to remember and dashboard filters are limited. | Show visual schema, clickable tables, relationships, and sample source rows. |
| Ask Natural-Language Query | She asks a supported business question and expects a reliable answer. | Hopeful 🙂 | Generic AI may invent columns, joins, or unsupported logic. | Use schema-aware intent and slot compilation for supported query families. |
| Wait For Processing | She waits while the system routes the question, compiles SQL, and retrieves data. | Impatient ⏳ | Waiting without feedback reduces trust in the final answer. | Show route, confidence, latency, and processing state before results appear. |
| Review SQL And Results | She checks the answer, generated SQL, and source rows before sharing insights. | Careful 🔍 | Answers need evidence before they can influence product or leadership decisions. | Display SQL, source rows, confidence, route, latency, and answer summary together. |
| Validate And Follow Up | She refines filters, compares rows, and asks follow-up questions across teams. | Confident ✅ | Manual SQL support slows every iteration and creates dependency on analysts. | Keep schema, data, chat, and follow-up workflow in one trusted workspace. |
Pain Points
Users do not know exact table names, column names, or relationships across product, sales, support, billing, and risk data.
Product and business users need many variations of a question, but every manual SQL request creates delay and analyst dependency.
Dashboards answer fixed questions well, but they break down when users need ad hoc filters, joins, or cross-functional follow-ups.
Users cannot act on black-box answers unless they can inspect the SQL, route, confidence, latency, and source rows behind the response.
Important questions often require joining accounts, invoices, orders, support tickets, and regional data, which is hard for non-technical users.
Users lose context when schema, data preview, chat, SQL output, and evidence rows are separated across multiple tools.
Pain Point Prioritization
| No. | Pain Point | Time | Effort |
|---|---|---|---|
| 01 | Schema Uncertainty | ||
| 02 | Slow Follow-Up Iteration | ||
| 03 | Limited Dashboard Flexibility | ||
| 04 | Low Answer Trust | ||
| 05 | Complex Manual Joins | ||
| 06 | Weak Workflow Continuity |
Solutions
OK Ideas
Helps understanding but does not answer questions directly.
Useful for repeated reporting, weak for ad hoc questions.
Organizes work but keeps waiting time and dependency.
Best Ideas
Converts natural language into safe SQL using known schema and allowed query families.
Shows table relationships, clickable tables, and sample source rows.
Shows answer summary, compiled SQL, confidence, route, latency, and source rows.
Moonshots
Company-specific small language model for schema-grounded business querying.
Connects CRM, billing, support, analytics, and warehouse data with permissions.
Detects risks, churn, anomalies, and revenue opportunities proactively.
Moonshot Prioritization
| No. | Moonshot | Time | Effort |
|---|---|---|---|
| 01 | DataTalk-SLM | ||
| 02 | Governed Enterprise Copilot | ||
| 03 | Autonomous Insight Agent |
Selected Solution
DataTalk-SLM
DataTalk-SLM is the selected solution because it directly connects user value, product feasibility, and schema-grounded AI. Instead of giving a generic AI chat answer, the system converts natural-language business questions into supported, verifiable data retrieval workflows.
Solution Architecture
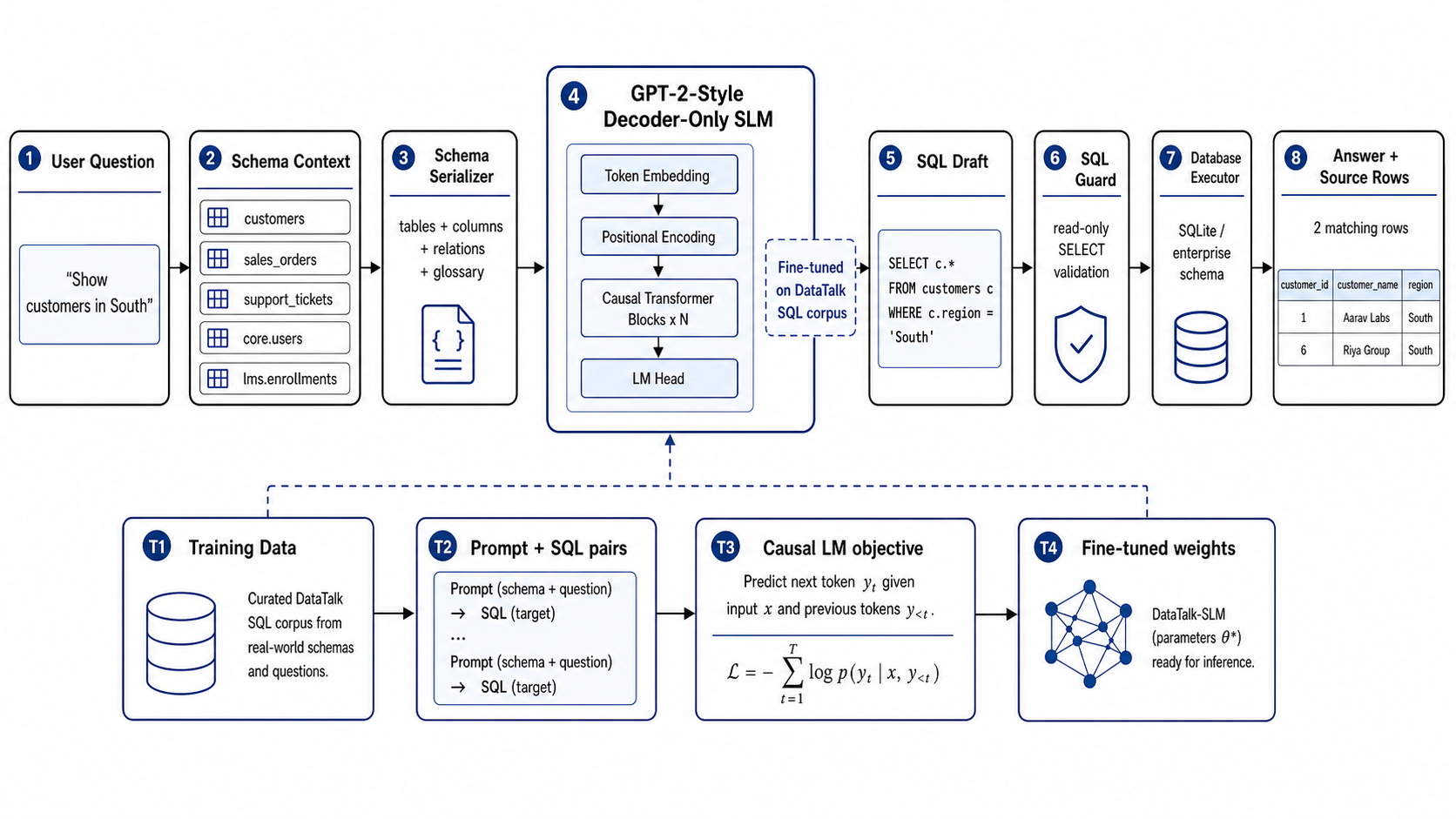
Solution Explanation
The system knows supported tables, columns, relationships, and query families before answering.
User questions are converted into constrained intent and slot structures instead of open-ended generation.
Every answer can show compiled SQL, source rows, route, confidence, and latency for trust.
Users can inspect schema, preview data, ask questions, and validate results in one workflow.
The future model can learn company schema and question patterns while keeping production querying controlled.
The product helps PMs and business teams reduce analyst dependency and move faster from question to decision.
Final Product Direction
DataTalk is a schema-aware data copilot that helps business teams move from natural-language questions to verified SQL-backed answers. The product direction is to evolve the current demo into DataTalk-SLM: a company-specific small language model trained for fast, grounded, and trustworthy business querying.